基本概念
排序算法可以分为以下两种类型:
- 比较类非线性时间排序:通过比较来决定元素间的相对次序,其时间复杂度不能突破$O(nlogn)$
- 非比较类线性时间排序:不通过比较来决定元素间的相对次序,其时间复杂度最低可以为$O(n)$
- 稳定性:如果排序前后两个相等元素的相对次序不变,则算法稳定;反之算法不稳定
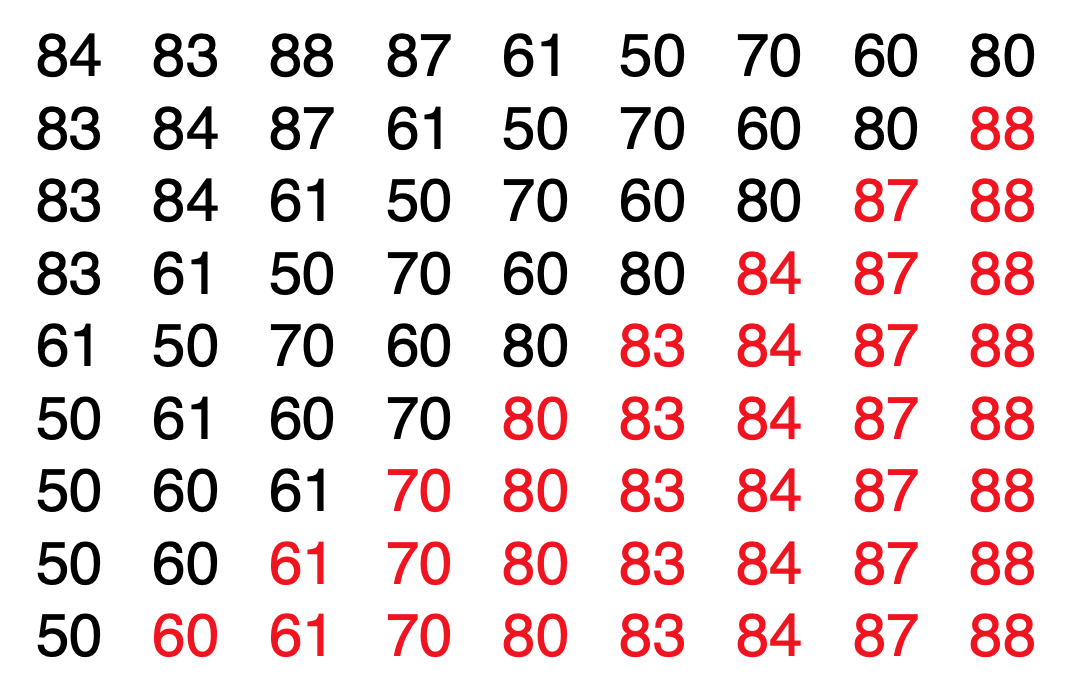
冒泡排序
- 实现步骤(从小到大排序):
- 从最前面的两个元素开始,不断对相邻元素进行比较,根据情况决定是否交换相邻元素的位置,直到最后。这会将最大的元素“冒泡”到元素列的末尾位置。
- 步骤 1 需要被重复执行 n-1 次。但是每一趟排序时,不是全部元素都需要进行比较的。例如,对于第 m 趟排序,此时元素列最后面的 m 个元素是已经完成排序了的,所以不需要对它们进行重复的比较。
- 最坏时间复杂度:$O(n^2)$
- 平均时间复杂度:$O(n^2)$
- 最好时间复杂度:$O(n)$
- 空间复杂度:$O(1)$
- 稳定性:稳定
1 | let list = [84, 83, 88, 87, 61, 50, 70, 60, 80]; |
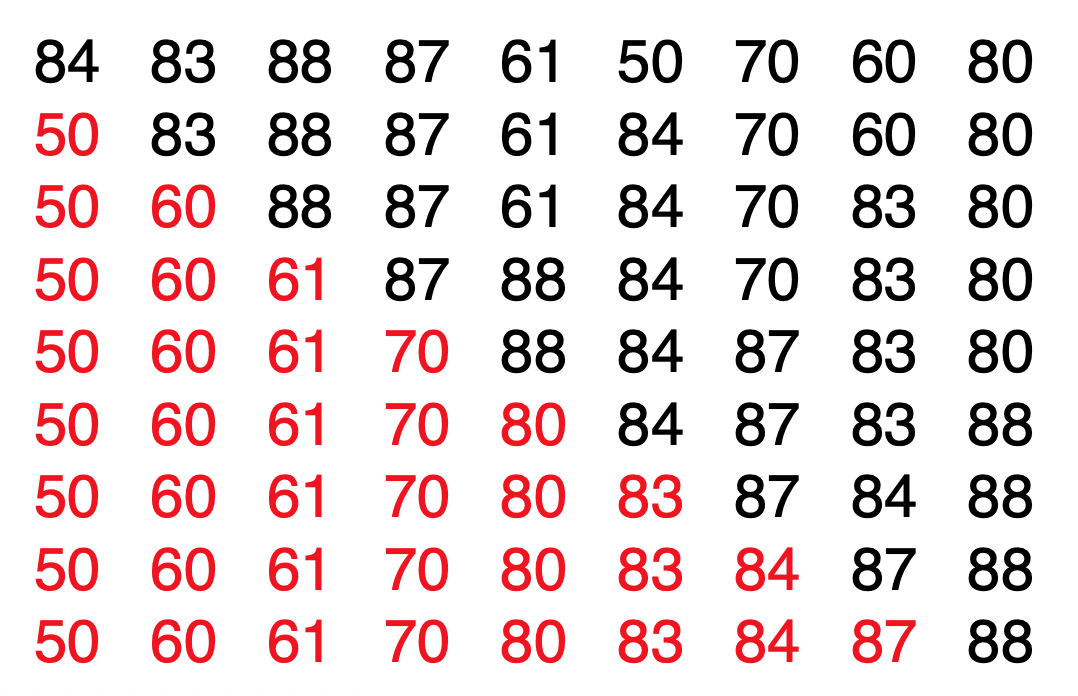
选择排序
- 实现步骤(从小到大排序):
- 共需要进行 n-1 次循环。每次循环都会选定一个起点元素,例如,第一次循环是以第一个元素为起点。第 m 次循环是以第 m 个元素为起点。
- 在每次循环中,找出本次循环中从起点元素开始到最后一个元素为止最小的元素,如果这个元素正是起点元素则什么都不做,否则交换起点元素与该最小元素的位置。
- 最坏时间复杂度:$O(n^2)$
- 平均时间复杂度:$O(n^2)$
- 最好时间复杂度:$O(n^2)$
- 空间复杂度:$O(1)$
- 稳定性:不稳定
1 | let list = [84, 83, 88, 87, 61, 50, 70, 60, 80]; |
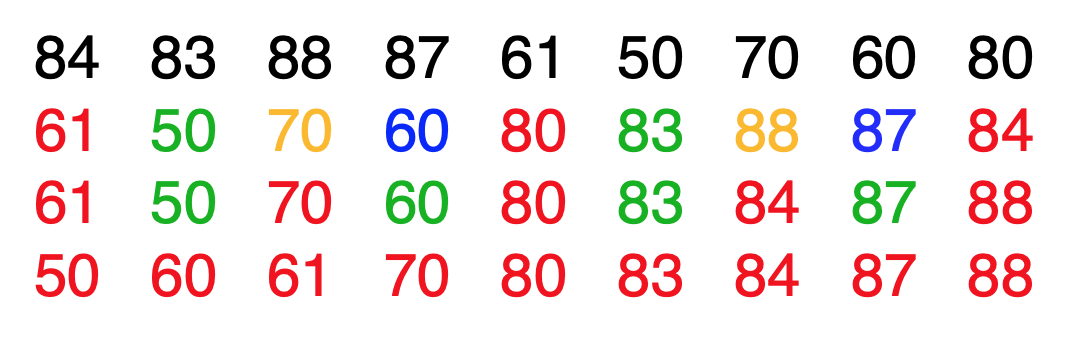
插入排序
- 实现步骤(从小到大排序):
- 共需要进行 n-1 次循环。每次循环都会选定一个待插入元素,例如,第一次循环是以第二个元素为待插入元素。第 m 次循环是以第 m+1 个元素为待插入元素。
- 在每次循环中,不断将待插入元素与处于它前方的元素进行比较,找出适合它的位置并插入。
- 最坏时间复杂度:$O(n^2)$
- 平均时间复杂度:$O(n^2)$
- 最好时间复杂度:$O(n)$
- 空间复杂度:$O(1)$
- 稳定性:稳定
1 | let list = [84, 83, 88, 87, 61, 50, 70, 60, 80]; |

希尔排序
- 实现步骤(从小到大排序):
- 按照步长
n/2 => n/4 => ··· => 1进行循环。每次循环中根据步长对元素列进行分组,然后对这些分组执行插入排序。
- 按照步长
- 最坏时间复杂度:$O(n^2)$
- 平均时间复杂度:$O(n^{1.3})$
- 最好时间复杂度:$O(n)$
- 空间复杂度:$O(1)$
- 稳定性:不稳定
1 | let list = [84, 83, 88, 87, 61, 50, 70, 60, 80]; |
归并排序
- 实现步骤(从小到大排序):
- 不断地将元素列分成两个部分,然后对这两个部分递归执行归并排序。
- 当元素列只有 1 个元素时,停止递归。
- 对于被划分的两个部分,需要按照顺序将它们合并为一个整体。
- 最坏时间复杂度:$O(nlogn)$
- 平均时间复杂度:$O(nlogn)$
- 最好时间复杂度:$O(nlogn)$
- 空间复杂度:$O(n)$
- 稳定性:稳定
1 | let list = [84, 83, 88, 87, 61, 50, 70, 60, 80]; |
快速排序
- 实现步骤(从小到大排序):
- 通过三数中值分割法,从元素列中选出最左侧,中间和最右侧的三个元素,并排序。
- 从步骤 1 中排序后的三个元素中选择中间元素作为枢纽元素,并交换枢纽元素和元素列倒数第二个元素的位置。
- 选择
i = left + 1, j = right - 2。 - 不断执行
i++操作,直到i所处元素大于等于枢纽元素为止。 - 不断执行
j--操作,直到j所处元素小于等于枢纽元素为止。 - 如果
i < j,那么交换这两个位置上的元素,然后重复执行步骤 4、5。 - 如果
i >= j,那么此刻位置i上的元素一定是大于等于枢纽元素的,此时交换位置i上的元素和枢纽元素的位置。交换之后,枢纽元素左侧的元素均小于等于它,而它右侧的元素均大于等于它。 - 不断对被枢纽元素分割开来的两个子元素列执行步骤 1 至步骤 7,直到排序完成。
- 最坏时间复杂度:$O(n^2)$
- 平均时间复杂度:$O(nlgn)$
- 最好时间复杂度:$O(nlgn)$
- 空间复杂度:$O(lgn)$ 至 $O(n)$ 之间
- 稳定性:不稳定
- 需要注意
array[i]=array[j]=pivot的情况,不要陷入死循环。 - 为什么当所遇元素与枢纽元素相等时,也要让
i和j停下来,并交换位置?
这样可以确保被枢纽元素分割开来的两部分尽量均衡,减少插入排序算法总的时间复杂度。
1 | let list = [84, 83, 88, 87, 61, 50, 70, 60, 80]; |
堆排序
- 实现步骤(从小到大排序):
- 首先将元素列转换为最大堆形式的数组。
- 数组中的最大元素总在 A[1] 中,把它与 A[heap.size] 进行互换,同时从堆中去掉最后一个结点(这一操作可以通过减少 heap.size 来实现)。
- 步骤 2 之后,最大堆的剩余结点中,原来根的孩子结点仍然是最大堆,而新的根节点可能会违背最大堆的性质。为了维护最大堆的性质,我们要做的就是通过下滤操作使其符合最大堆的性质。
- 重复步骤 2、3,直到 heap.size = 1。
- 最坏时间复杂度:$O(nlgn)$
- 平均时间复杂度:$O(nlgn)$
- 最好时间复杂度:$O(nlgn)$
- 空间复杂度:$O(1)$
- 稳定性:不稳定
1 | let list = [90, 84, 83, 88, 87, 61, 50, 70, 60, 80]; |
计数排序
- 实现步骤(从小到大排序):
- 假设元素列中的元素均处于 $[0, k]$ 区间内,$k$ 为某个整数。
- 准备一个长度为 $k+1$ 的数组 temp,索引为 $i$ 处记录着元素列中值为 $i$ 的元素的个数。
- 调整数组 temp,使得索引为 $i$ 处记录着元素列中值小于等于 $i$ 的元素的个数。
- 准备一个长度为 $n$ 的数组 res 用于存储排序后的元素列,然后从后至前的迭代待排序的元素列,根据 temp 确定每次迭代的元素应该处于哪个位置,同时对 temp 进行适当的修改。
- 时间复杂度:$\Theta(n+k)$
- 空间复杂度:$O(n+k)$
- 稳定性:稳定
1 | let list = [2, 5, 3, 0, 2, 3, 0, 3]; |
桶排序
- 实现步骤(从小到大排序):
- 假设元素列中的元素均处于 $[0, 1)$ 区间内。
- 准备一个长度为 10 的数组 temp。
- 假设元素的值为 $x$,则将它放入 temp 数组索引为 $\lfloor 10x \rfloor$ 的位置。
- 对数组 temp 下的每个“桶”进行排序,然后将排序后的“桶”拼接在一起。
- 时间复杂度:需要考虑每个桶内排序所消耗的时间
- 空间复杂度:$O(n+k)$
- 稳定性:稳定
1 | let list = [0.78, 0.17, 0.39, 0.26, 0.72, 0.94, 0.21, 0.12, 0.23, 0.68]; |
基数排序
- 实现步骤(从小到大排序):
- 从最低有效位开始,依次根据当前位的关键字对元素列使用稳定排序算法进行排序。
- 时间复杂度:
- 给定 $n$ 个 $d$ 位数,其中每一个数位有 $k$ 个可能的取值。如果使用的稳定排序方法耗时 $\Theta(n+k)$,那么它就可以在 $\Theta(d(n+k))$ 时间内将这些数排好序。
- 给定一个 $b$ 位数和任何正整数 $r \leq b$,如果使用稳定排序算法对数据取值区间为 $[0, k]$ 的输入进行排序耗时 $\Theta(n+k)$,那么它就可以在 $\Theta((b/r)(n+2^r))$ 时间内将这些数排好序。
- 空间复杂度:由过程中使用的稳定排序算法决定
- 稳定性:稳定
1 | let list = [329, 457, 657, 839, 436, 720, 355, 11, 20, 4]; |

